publications
List of publications in reversed chronological order.
2026
-
 Off The Grid: Detection of Primitives for Feed-Forward 3D Gaussian SplattingCVPR, 2026
Off The Grid: Detection of Primitives for Feed-Forward 3D Gaussian SplattingCVPR, 2026Feed-forward 3D Gaussian Splatting (3DGS) models enable real-time scene generation but are hindered by suboptimal pixel-aligned primitive placement, which relies on a dense, rigid grid and limits both quality and efficiency. We introduce a new feed-forward architecture that detects 3D Gaussian primitives at a sub-pixel level, replacing the pixel grid with an adaptive, "Off The Grid" distribution. Inspired by keypoint detection, our multi-resolution decoder learns to distribute primitives across image patches. This module is trained end-to-end with a 3D reconstruction backbone using self-supervised learning. Our resulting pose-free model generates photorealistic scenes in seconds, achieving state-of-the-art novel view synthesis for feed-forward models. It outperforms competitors while using far fewer primitives, demonstrating a more accurate and efficient allocation that captures fine details and reduces artifacts. Moreover, we observe that by learning to render 3D Gaussians, our 3D reconstruction backbone improves camera pose estimation, suggesting opportunities to train these foundational models without labels.
-
 Charge: A Comprehensive Novel View Synthesis Benchmark and Dataset to Bind Them AllCVPR, 2026
Charge: A Comprehensive Novel View Synthesis Benchmark and Dataset to Bind Them AllCVPR, 2026This paper presents a new dataset for Novel View Synthesis, generated from a high-quality, animated film with stunning realism and intricate detail. Our dataset captures a variety of dynamic scenes, complete with detailed textures, lighting, and motion, making it ideal for training and evaluating cutting-edge 4D scene reconstruction and novel view generation models. In addition to high-fidelity RGB images, we provide multiple complementary modalities, including depth, surface normals, object segmentation and optical flow, enabling a deeper understanding of scene geometry and motion. The dataset is organised into three distinct benchmarking scenarios: a dense multi-view camera setup, a sparse camera arrangement, and monocular video sequences, enabling a wide range of experimentation and comparison across varying levels of data sparsity. With its combination of visual richness, high-quality annotations, and diverse experimental setups, this dataset offers a unique resource for pushing the boundaries of view synthesis and 3D vision.
-
 CHROMA: Consistent Harmonization of Multi-View Appearance via Bilateral Grid PredictionICLR, 2026
CHROMA: Consistent Harmonization of Multi-View Appearance via Bilateral Grid PredictionICLR, 2026Modern camera pipelines apply extensive on-device processing, such as exposure adjustment, white balance, and color correction, which, while beneficial individually, often introduce photometric inconsistencies across views. These appearance variations violate multi-view consistency and degrade novel view synthesis. Joint optimization of scene-specific representations and per-image appearance embeddings has been proposed to address this issue, but with increased computational complexity and slower training. In this work, we propose a generalizable, feed-forward approach that predicts spatially adaptive bilateral grids to correct photometric variations in a multi-view consistent manner. Our model processes hundreds of frames in a single step, enabling efficient large-scale harmonization, and seamlessly integrates into downstream 3D reconstruction models, providing cross-scene generalization without requiring scene-specific retraining. To overcome the lack of paired data, we employ a hybrid self-supervised rendering loss leveraging 3D foundation models, improving generalization to real-world variations. Extensive experiments show that our approach outperforms or matches the reconstruction quality of existing scene-specific optimization methods with appearance modeling, without significantly affecting the training time of baseline 3D models.
-
 An Interactive Conversational 3D Virtual HumanIJCV, 2026
An Interactive Conversational 3D Virtual HumanIJCV, 2026This work presents Interactive Conversational 3D Virtual Human (ICo3D), a method for generating an interactive, conversational, and photorealistic 3D human avatar. Based on multi-view captures of a subject, we create an animatable 3D face model and a dynamic 3D body model, both rendered by splatting Gaussian primitives. Once merged together, they represent a lifelike virtual human avatar suitable for real-time user interactions. We equip our avatar with an LLM for conversational ability. During conversation, the audio speech of the avatar is used as a driving signal to animate the face model, enabling precise synchronization. We describe improvements to our dynamic Gaussian models that enhance photorealism: SWinGS++ for body reconstruction and HeadGaS++ for face reconstruction, and provide as well a solution to merge the separate face and body models without artifacts. We also present a demo of the complete system, showcasing several use cases of real-time conversation with the 3D avatar. Our approach offers a fully integrated virtual avatar experience, supporting both oral and written form interactions in immersive environments. ICo3D is applicable to a wide range of fields, including gaming, virtual assistance, and personalized education, among others.
-
 SCENIC: Scene-aware Semantic Navigation with Instruction-guided Control3DV, 2026
SCENIC: Scene-aware Semantic Navigation with Instruction-guided Control3DV, 2026Synthesizing natural human motion that adapts to complex environments while allowing creative control remains a fundamental challenge in motion synthesis. Existing models often fall short, either by assuming flat terrain or lacking the ability to control motion semantics through text. To address these limitations, we introduce SCENIC, a diffusion model designed to generate human motion that adapts to dynamic terrains within virtual scenes while enabling semantic control through natural language. The key technical challenge lies in simultaneously reasoning about complex scene geometry while maintaining text control. This requires understanding both high-level navigation goals and fine-grained environmental constraints. The model must ensure physical plausibility and precise navigation across varied terrain, while also preserving user-specified text control, such as “carefully stepping over obstacles" or “walking upstairs like a zombie." Our solution introduces a hierarchical scene reasoning approach. At its core is a novel scene-dependent, goal-centric canonicalization that handles high-level goal constraint, and is complemented by an ego-centric distance field that captures local geometric details. This dual representation enables our model to generate physically plausible motion across diverse 3D scenes. By implementing frame-wise text alignment, our system achieves seamless transitions between different motion styles while maintaining scene constraints. Experiments demonstrate our novel diffusion model generates arbitrarily long human motions that both adapt to complex scenes with varying terrain surfaces and respond to textual prompts. Additionally, we show SCENIC can generalize to four real-scene datasets.
2025
-
 ViDAR: Video Diffusion-Aware 4D Reconstruction From Monocular InputsNeurIPS, 2025
ViDAR: Video Diffusion-Aware 4D Reconstruction From Monocular InputsNeurIPS, 2025Dynamic Novel View Synthesis aims to generate photorealistic views of moving subjects from arbitrary viewpoints. This task is particularly challenging when relying on monocular video, where disentangling structure from motion is ill-posed and supervision is scarce. We introduce Video Diffusion-Aware Reconstruction (ViDAR), a novel 4D reconstruction framework that leverages personalised diffusion models to synthesise a pseudo multi-view supervision signal for training a Gaussian splatting representation. By conditioning on scene-specific features, ViDAR recovers fine-grained appearance details while mitigating artefacts introduced by monocular ambiguity. To address the spatio-temporal inconsistency of diffusion-based supervision, we propose a diffusion-aware loss function and a camera pose optimisation strategy that aligns synthetic views with the underlying scene geometry. Experiments on DyCheck, a challenging benchmark with extreme viewpoint variation, show that ViDAR outperforms all state-of-the-art baselines in visual quality and geometric consistency. We further highlight ViDAR’s strong improvement over baselines on dynamic regions and provide a new benchmark to compare performance in reconstructing motion-rich parts of the scene.
-
 CoMapGS: Covisibility Map-based Gaussian Splatting for Sparse Novel View SynthesisY Jang, and E Pérez-PelliteroCVPR, 2025
CoMapGS: Covisibility Map-based Gaussian Splatting for Sparse Novel View SynthesisY Jang, and E Pérez-PelliteroCVPR, 2025We propose Covisibility Map-based Gaussian Splatting (CoMapGS), designed to recover underrepresented sparse regions in sparse novel view synthesis. CoMapGS addresses both high- and low-uncertainty regions by constructing covisibility maps, enhancing initial point clouds, and applying uncertainty-aware weighted supervision using a proximity classifier. Our contributions are threefold: (1) CoMapGS reframes novel view synthesis by leveraging covisibility maps as a core component to address region-specific uncertainty; (2) Enhanced initial point clouds for both low- and high-uncertainty regions compensate for sparse COLMAP-derived point clouds, improving reconstruction quality and benefiting few-shot 3DGS methods; (3) Adaptive supervision with covisibility-score-based weighting and proximity classification achieves consistent performance gains across scenes with varying sparsity scores derived from covisibility maps. Experimental results demonstrate that CoMapGS outperforms state-of-the-art methods on datasets including Mip-NeRF 360 and LLFF.
-
 GASPACHO: Gaussian Splatting for Controllable Humans and ObjectsarXiv:2503.09342 [cs.CV], 2025
GASPACHO: Gaussian Splatting for Controllable Humans and ObjectsarXiv:2503.09342 [cs.CV], 2025We present GASPACHO: a method for generating photorealistic controllable renderings of human-object interactions. Given a set of multi-view RGB images of human-object interactions, our method reconstructs animatable templates of the human and object as separate sets of Gaussians simultaneously. Different from existing work, which focuses on human reconstruction and ignores objects as background, our method explicitly reconstructs both humans and objects, thereby allowing for controllable renderings of novel human object interactions in different poses from novel-camera viewpoints. During reconstruction, we constrain the Gaussians that generate rendered images to be a linear function of a set of canonical Gaussians. By simply changing the parameters of the linear deformation functions after training, our method can generate renderings of novel human-object interaction in novel poses from novel camera viewpoints. We learn the 3D Gaussian properties of the canonical Gaussians on the underlying 2D manifold of the canonical human and object templates. This in turns requires a canonical object template with a fixed UV unwrapping. To define such an object template, we use a feature based representation to track the object across the multi-view sequence. We further propose an occlusion aware photometric loss that allows for reconstructions under significant occlusions. Several experiments on two human-object datasets - BEHAVE and DNA-Rendering - demonstrate that our method allows for high-quality reconstruction of human and object templates under significant occlusion and the synthesis of controllable renderings of novel human-object interactions in novel human poses from novel camera views.
-
 FORCE: Physics-aware Human-object Interaction3DV, 2025
FORCE: Physics-aware Human-object Interaction3DV, 2025Interactions between human and objects are influenced not only by the object’s pose and shape, but also by physical attributes such as object mass and surface friction. They introduce important motion nuances that are essential for diversity and realism. Despite advancements in recent human-object interaction methods, this aspect has been overlooked.Generating nuanced human motion presents two challenges. First, it is non-trivial to learn from multi-modal human and object information derived from both the physical and non-physical attributes. Second, there exists no dataset capturing nuanced human interactions with objects of varying physical properties, hampering model development.This work addresses the gap by introducing the FORCE model, an approach for synthesizing diverse, nuanced human-object interactions by modeling physical attributes. Our key insight is that human motion is dictated by the interrelation between the force exerted by the human and the perceived resistance. Guided by a novel intuitive physics encoding, the model captures the interplay between human force and resistance. Experiments also demonstrate incorporating human force facilitates learning multi-class motion.Accompanying our model, we contribute the a dataset, which features diverse, different-styled motion through interactions with varying resistances. Our code, dataset, and models will be released to foster future research.
-
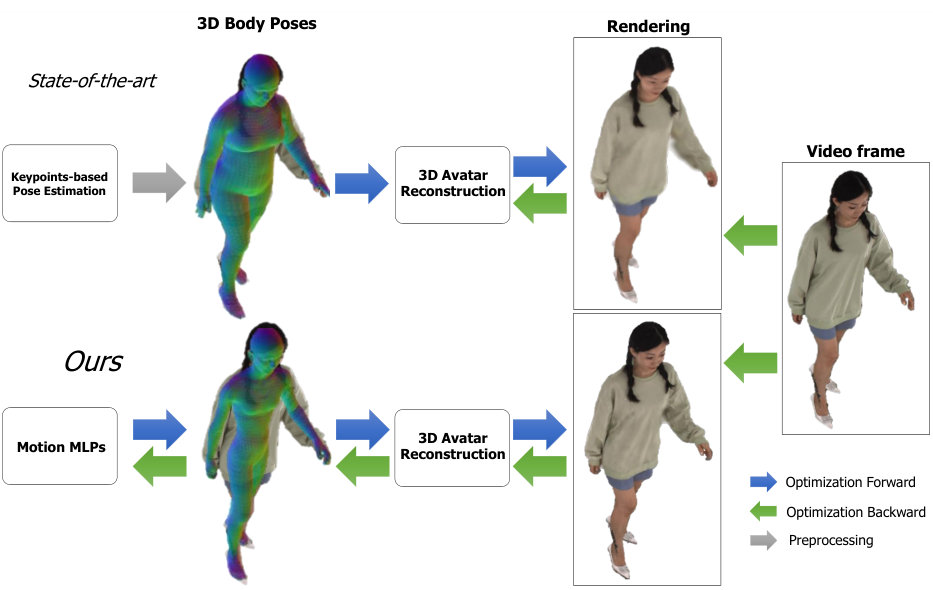 Better Together: Unified Motion Capture and 3D Avatar ReconstructionarXiv:2503.09293 [cs.CV], 2025
Better Together: Unified Motion Capture and 3D Avatar ReconstructionarXiv:2503.09293 [cs.CV], 2025We present Better Together, a method that simultaneously solves the human pose estimation problem while reconstructing a photorealistic 3D human avatar from multi-view videos. While prior art usually solves these problems separately, we argue that joint optimization of skeletal motion with a 3D renderable body model brings synergistic effects, i.e. yields more precise motion capture and improved visual quality of real-time rendering of avatars. To achieve this, we introduce a novel animatable avatar with 3D Gaussians rigged on a personalized mesh and propose to optimize the motion sequence with time-dependent MLPs that provide accurate and temporally consistent pose estimates. We first evaluate our method on highly challenging yoga poses and demonstrate state-of-the-art accuracy on multi-view human pose estimation, reducing error by 35% on body joints and 45% on hand joints compared to keypoint-based methods. At the same time, our method significantly boosts the visual quality of animatable avatars (+2dB PSNR on novel view synthesis) on diverse challenging subjects.
2024
-
 SCRREAM : SCan, Register, REnder And Map: A Framework for Annotating Accurate and Dense 3D Indoor Scenes with a BenchmarkH Jung, W Li, S-C Wu, W Bittner, N Brasch, J Song, E Pérez-Pellitero, Z Zhang, A Moreau, N Navab, and B BusamNeurIPS (Dataset and Benchmarks), 2024
SCRREAM : SCan, Register, REnder And Map: A Framework for Annotating Accurate and Dense 3D Indoor Scenes with a BenchmarkH Jung, W Li, S-C Wu, W Bittner, N Brasch, J Song, E Pérez-Pellitero, Z Zhang, A Moreau, N Navab, and B BusamNeurIPS (Dataset and Benchmarks), 2024Traditionally, 3d indoor datasets have generally prioritized scale over ground-truth accuracy in order to obtain improved generalization. However, using these datasets to evaluate dense geometry tasks, such as depth rendering, can be problematic as the meshes of the dataset are often incomplete and may produce wrong ground truth to evaluate the details. In this paper, we propose SCRREAM, a dataset annotation framework that allows annotation of fully dense meshes of objects in the scene and registers camera poses on the real image sequence, which can produce accurate ground truth for both sparse 3D as well as dense 3D tasks. We show the details of the dataset annotation pipeline and showcase four possible variants of datasets that can be obtained from our framework with example scenes, such as indoor reconstruction and SLAM, scene editing and object removal, human reconstruction and 6d pose estimation. Recent pipelines for indoor reconstruction and SLAM serve as new benchmarks. In contrast to previous indoor dataset, our design allows to evaluate dense geometry tasks on eleven sample scenes against accurately rendered ground truth depth maps.
-
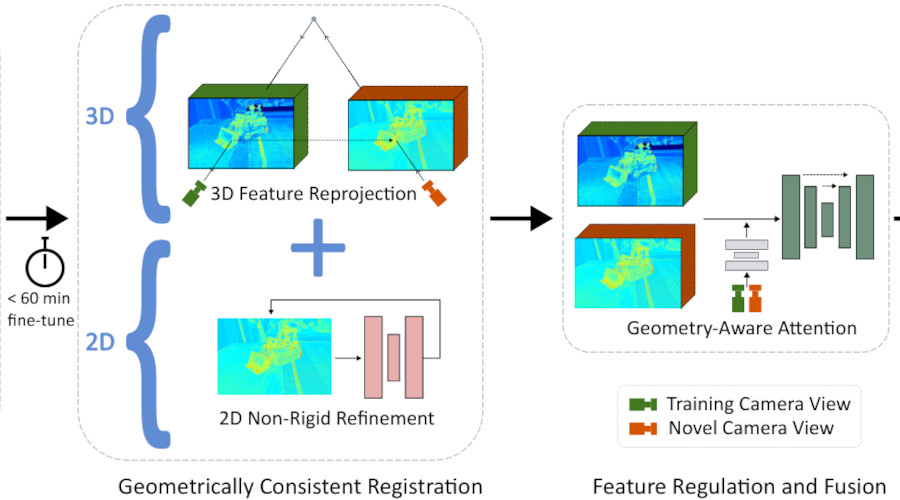 RoGUENeRF: A Robust Geometry-Consistent Universal Enhancer for NeRFECCV, 2024
RoGUENeRF: A Robust Geometry-Consistent Universal Enhancer for NeRFECCV, 2024Recent advances in neural rendering have enabled highly photorealistic 3D scene reconstruction and novel view synthesis. Despite this progress, current state-of-the-art methods struggle to reconstruct high frequency detail, due to factors such as a low-frequency bias of radiance fields and inaccurate camera calibration. One approach to mitigate this issue is to enhance images post-rendering. 2D enhancers can be pre-trained to recover some detail but are agnostic to scene geometry and do not easily generalize to new distributions of image degradation. Conversely, existing 3D enhancers are able to transfer detail from nearby training images in a generalizable manner, but suffer from inaccurate camera calibration and can propagate errors from the geometry into rendered images. We propose a neural rendering enhancer, RoGUENeRF, which exploits the best of both paradigms. Our method is pre-trained to learn a general enhancer while also leveraging information from nearby training images via robust 3D alignment and geometry-aware fusion. Our approach restores high-frequency textures while maintaining geometric consistency and is also robust to inaccurate camera calibration. We show that RoGUENeRF substantially enhances the rendering quality of a wide range of neural rendering baselines, e.g. improving the PSNR of MipNeRF360 by 0.63dB and Nerfacto by 1.34dB on the real world 360v2 dataset.
-
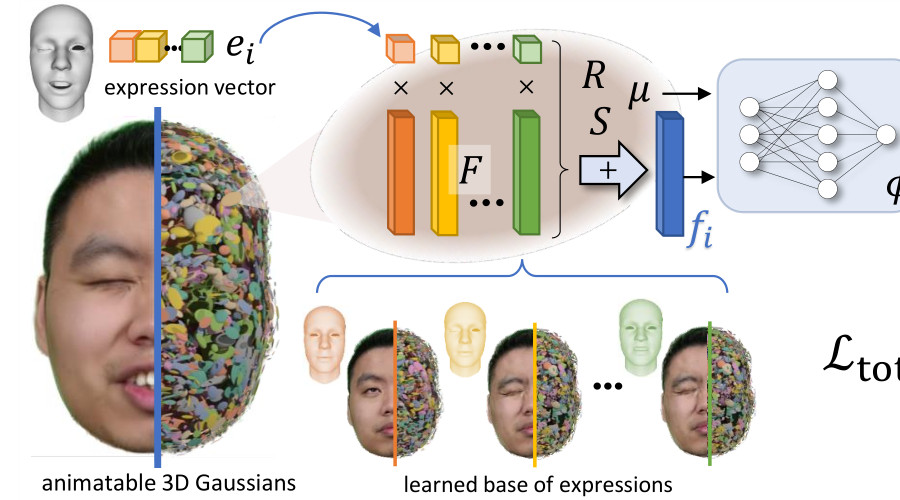 HeadGaS: Real-Time Animatable Head Avatars via 3D Gaussian SplattingECCV, 2024
HeadGaS: Real-Time Animatable Head Avatars via 3D Gaussian SplattingECCV, 20243D head animation has seen major quality and runtime improvements over the last few years, particularly empowered by the advances in differentiable rendering and neural radiance fields. Real-time rendering is a highly desirable goal for real-world applications. We propose HeadGaS, the first model to use 3D Gaussian Splats (3DGS) for 3D head reconstruction and animation. In this paper we introduce a hybrid model that extends the explicit representation from 3DGS with a base of learnable latent features, which can be linearly blended with low-dimensional parameters from parametric head models to obtain expression-dependent final color and opacity values. We demonstrate that HeadGaS delivers state-of-the-art results in real-time inference frame rates, which surpasses baselines by up to 2dB, while accelerating rendering speed by over x10.
-
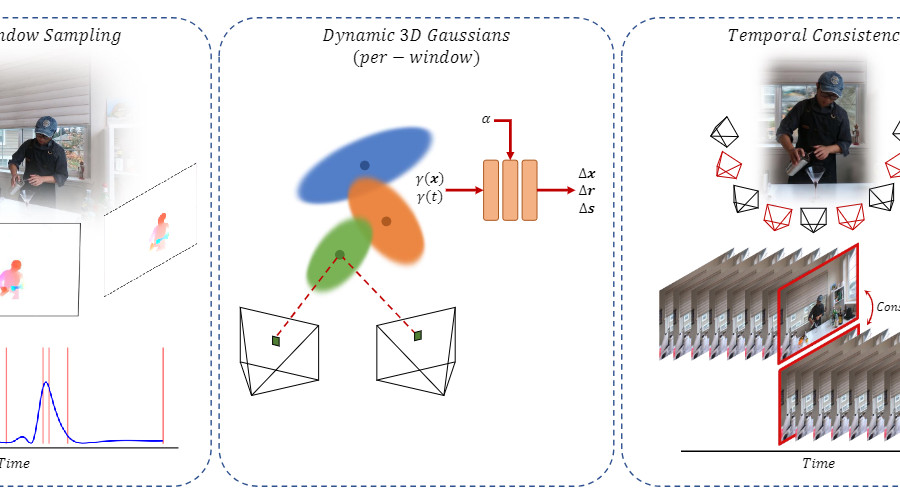 SWinGS: Sliding Windows for Dynamic 3D Gaussian SplattingECCV, 2024
SWinGS: Sliding Windows for Dynamic 3D Gaussian SplattingECCV, 2024Novel view synthesis has shown rapid progress recently, with methods capable of producing increasingly photorealistic results. 3D Gaussian Splatting has emerged as a promising method, producing high-quality renderings of scenes and enabling interactive viewing at real-time frame rates. However, it is limited to static scenes. In this work, we extend 3D Gaussian Splatting to reconstruct dynamic scenes. We model a scene’s dynamics using dynamic MLPs, learning deformations from temporally-local canonical representations to per-frame 3D Gaussians. To disentangle static and dynamic regions, tuneable parameters weigh each Gaussian’s respective MLP parameters, improving the dynamics modelling of imbalanced scenes. We introduce a sliding window training strategy that partitions the sequence into smaller manageable windows to handle arbitrary length scenes while maintaining high rendering quality. We propose an adaptive sampling strategy to determine appropriate window size hyperparameters based on the scene’s motion, balancing training overhead with visual quality. Training a separate dynamic 3D Gaussian model for each sliding window allows the canonical representation to change, enabling the reconstruction of scenes with significant geometric changes. Temporal consistency is enforced using a fine-tuning step with self-supervising consistency loss on randomly sampled novel views. As a result, our method produces high-quality renderings of general dynamic scenes with competitive quantitative performance, which can be viewed in real-time in our dynamic interactive viewer.
-
 AIM 2024 Sparse Neural Rendering Challenge: Dataset and BenchmarkECCV Workshops, 2024
AIM 2024 Sparse Neural Rendering Challenge: Dataset and BenchmarkECCV Workshops, 2024Recent developments in differentiable and neural rendering have made impressive breakthroughs in a variety of 2D and 3D tasks, e.g. novel view synthesis, 3D reconstruction. Typically, differentiable rendering relies on a dense viewpoint coverage of the scene, such that the geometry can be disambiguated from appearance observations alone. Several challenges arise when only a few input views are available, often referred to as sparse or few-shot neural rendering. As this is an underconstrained problem, most existing approaches introduce the use of regularisation, together with a diversity of learnt and hand-crafted priors. A recurring problem in sparse rendering literature is the lack of an homogeneous, up-to-date, dataset and evaluation protocol. While high-resolution datasets are standard in dense reconstruction literature, sparse rendering methods often evaluate with low-resolution images. Additionally, data splits are inconsistent across different manuscripts, and testing ground-truth images are often publicly available, which may lead to over-fitting. In this work, we propose the Sparse Rendering (SpaRe) dataset and benchmark. We introduce a new dataset that follows the setup of the DTU MVS dataset. The dataset is composed of 97 new scenes based on synthetic, high-quality assets. Each scene has up to 64 camera views and 7 lighting configurations, rendered at 1600x1200 resolution. We release a training split of 82 scenes to foster generalizable approaches, and provide an online evaluation platform for the validation and test sets, whose ground-truth images remain hidden. We propose two different sparse configurations (3 and 9 input images respectively). This provides a powerful and convenient tool for reproducible evaluation, and enable researchers easy access to a public leaderboard with the state-of-the-art performance scores. Available at: https://sparebenchmark.github.io/
-
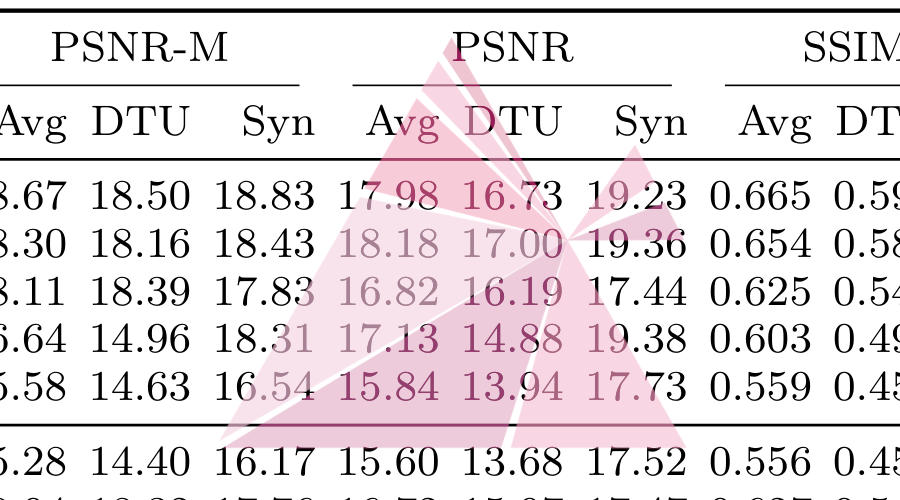 AIM 2024 Sparse Neural Rendering Challenge: Methods and ResultsECCV Workshops, 2024
AIM 2024 Sparse Neural Rendering Challenge: Methods and ResultsECCV Workshops, 2024This paper reviews the challenge on Sparse Neural Rendering that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2024. This manuscript focuses on the competition set-up, the proposed methods and their respective results. The challenge aims at producing novel camera view synthesis of diverse scenes from sparse image observations. It is composed of two tracks, with differing levels of sparsity; 3 views in Track 1 (very sparse) and 9 views in Track 2 (sparse). Participants are asked to optimise objective fidelity to the ground-truth images as measured via the Peak Signal-to-Noise Ratio (PSNR) metric. For both tracks, we use the newly introduced Sparse Rendering (SpaRe) dataset and the popular DTU MVS dataset. In this challenge, 5 teams submitted final results to Track 1 and 4 teams submitted final results to Track 2. The submitted models are varied and push the boundaries of the current state-of-the-art in sparse neural rendering. A detailed description of all models developed in the challenge is provided in this paper.
-
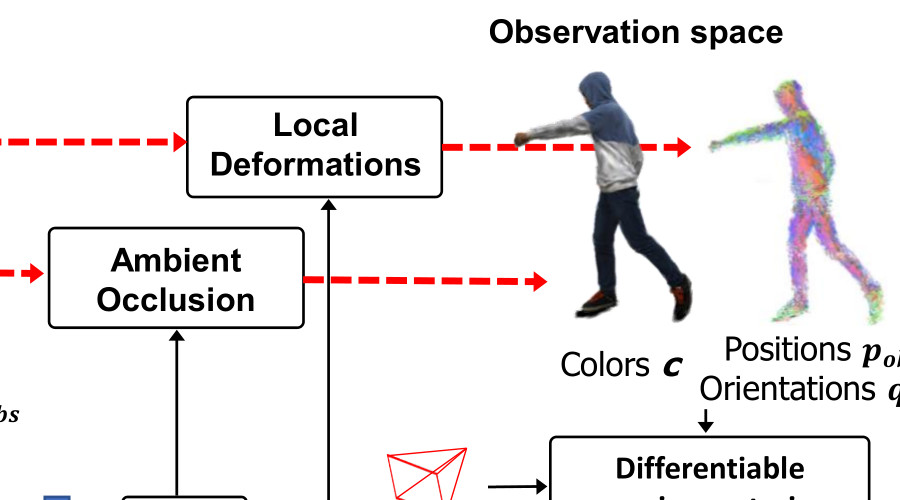 Human Gaussian Splatting: Real-time Rendering of Animatable AvatarsCVPR, 2024
Human Gaussian Splatting: Real-time Rendering of Animatable AvatarsCVPR, 2024This work addresses the problem of real-time rendering of photorealistic human body avatars learned from multi-view videos. While the classical approaches to model and render virtual humans generally use a textured mesh, recent research has developed neural body representations that achieve impressive visual quality. However, these models are difficult to render in real-time and their quality degrades when the character is animated with body poses different than the training observations. We propose the first animatable human model based on 3D Gaussian Splatting, that has recently emerged as a very efficient alternative to neural radiance fields. Our body is represented by a set of gaussian primitives in a canonical space which are deformed in a coarse to fine approach that combines forward skinning and local non-rigid refinement. We describe how to learn our Human Gaussian Splatting (HuGS) model in an end-to-end fashion from multi-view observations, and evaluate it against the state-of-the-art approaches for novel pose synthesis of clothed body. Our method presents a PSNR 1.5dbB better than the state-of-the-art on THuman4 dataset while being able to render at 20fps or more.
-
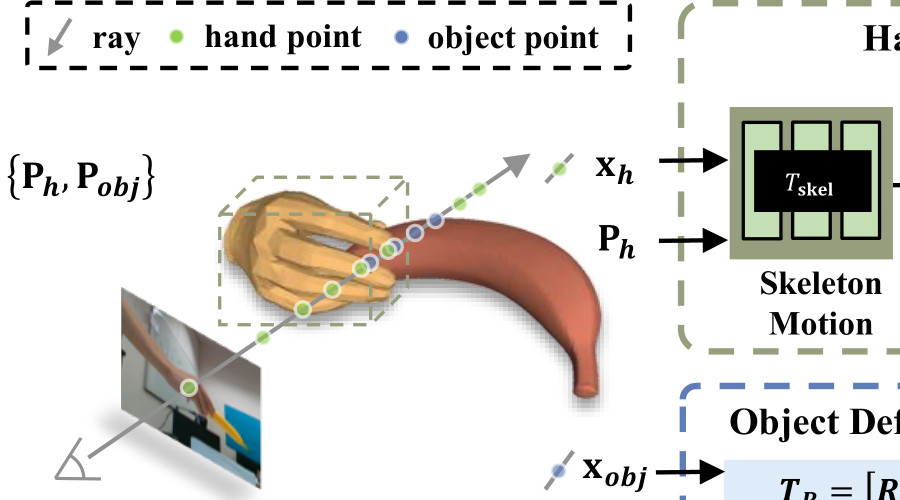 NCRF: Neural Contact Radiance Fields for Free-viewpoint Rendering of Hand-Object Interactions3DV, 2024
NCRF: Neural Contact Radiance Fields for Free-viewpoint Rendering of Hand-Object Interactions3DV, 2024Modelling hand-object interaction is a fundamental challenging task in 3D computer vision. Despite remarkable progress has been achieved in this field, existing methods still fail to synthesize the hand-object interaction photo-realistically, suffering from degraded rendering quality caused by the heavy mutual occlusions between hand and object, and inaccurate hand-object pose estimation. To tackle these challenges, we present a novel free-viewpoint rendering framework, Neural Contact Radiance Field (NCRF), to reconstruct hand-object interactions from a sparse set of videos. In particular, the proposed NCRF framework consists of two key components: (a) A contact optimization field that predicts an accurate contact field from 3D query points for achieving desirable contact between hand and object. (b) A hand-object neural radiance field to learn an implicit hand-object representation in a static canonical space, in concert with the specifically designed hand-object motion field to produce observation-to-canonical correspondences. We jointly learn these key components where they mutually help and regularize each other with visual and geometric constraints, producing a high-quality hand-object reconstruction with photo-realistic novel view synthesis. Extensive experiments on HO3D and DexYCB datasets show that our approach outperforms the current state-of-the-art in terms of both rendering quality and pose estimation accuracy.
2023
-
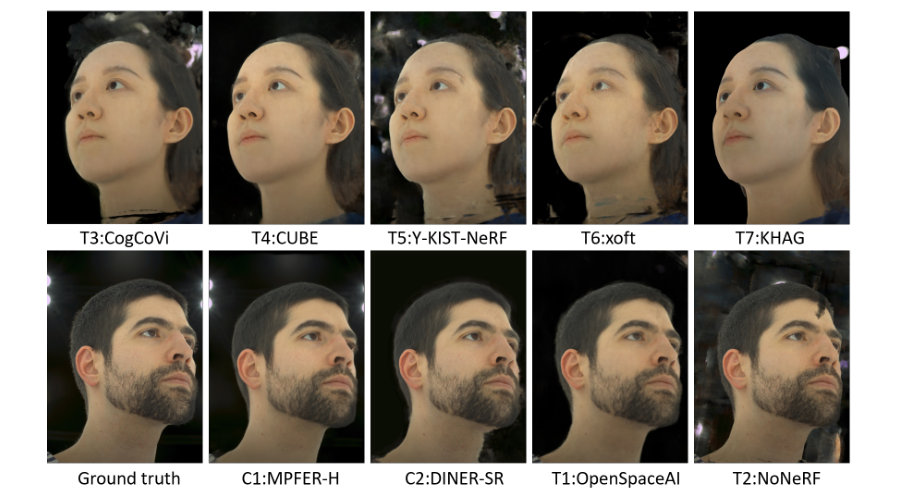 VSCHH 2023: A Benchmark for the View Synthesis Challenge of Human HeadsICCV Workshops, 2023
VSCHH 2023: A Benchmark for the View Synthesis Challenge of Human HeadsICCV Workshops, 2023This manuscript presents the results of the "A View Synthesis Challenge for Humans Heads (VSCHH)", which was part of the ICCV 2023 workshops. This paper describes the competition setup and provides details on replicating our initial baseline, TensoRF. Additionally, we provide a summary of the participants’ methods and their results in our benchmark table. The challenge aimed to synthesize novel camera views of human heads using a given set of sparse training view images. The proposed solutions of the participants were evaluated and ranked based on objective fidelity metrics, such as PSNR and SSIM, computed against unseen validation and test sets. In the supplementary material, we detailed the methods used by all participants in the VSCHH challenge, which opened on May 15th, 2023, and concluded on July 24th, 2023.
2022
-
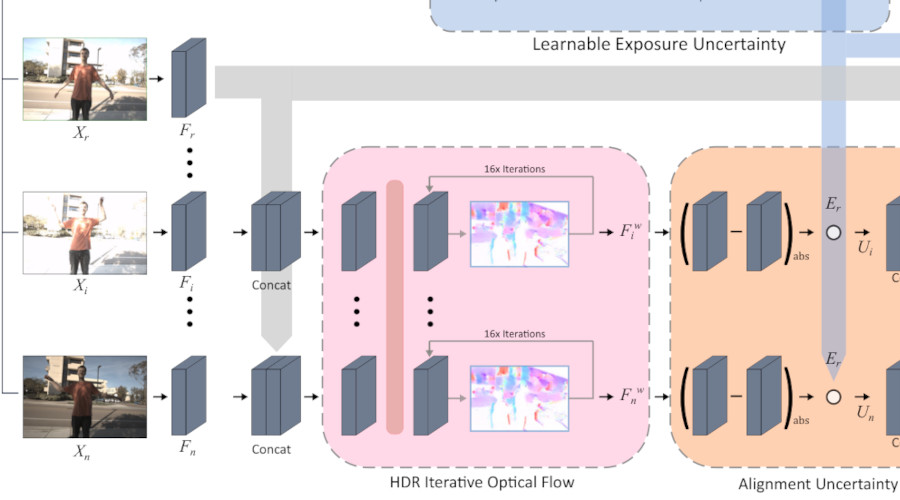 FlexHDR: Modelling Alignment and Exposure Uncertainties for Flexible HDR ImagingIEEE Trans. on Image Processing, 2022
FlexHDR: Modelling Alignment and Exposure Uncertainties for Flexible HDR ImagingIEEE Trans. on Image Processing, 2022High dynamic range (HDR) imaging is of fundamental importance in modern digital photography pipelines and used to produce a high-quality photograph with well exposed regions despite varying illumination across the image. This is typically achieved by merging multiple low dynamic range (LDR) images taken at different exposures. However, over-exposed regions and misalignment errors due to poorly compensated motion result in artefacts such as ghosting. In this paper, we present a new HDR imaging technique that specifically models alignment and exposure uncertainties to produce high quality HDR results. We introduce a strategy that learns to jointly align and assess the alignment and exposure reliability using an HDR-aware, uncertainty-driven attention map that robustly merges the frames into a single high quality HDR image. Further, we introduce a progressive, multi-stage image fusion approach that can flexibly merge any number of LDR images in a permutation-invariant manner. Experimental results show our method can produce better quality HDR images with up to 0.8dB PSNR improvement to the state-of-the-art, and subjective improvements in terms of better detail, colours, and fewer artefacts.
-
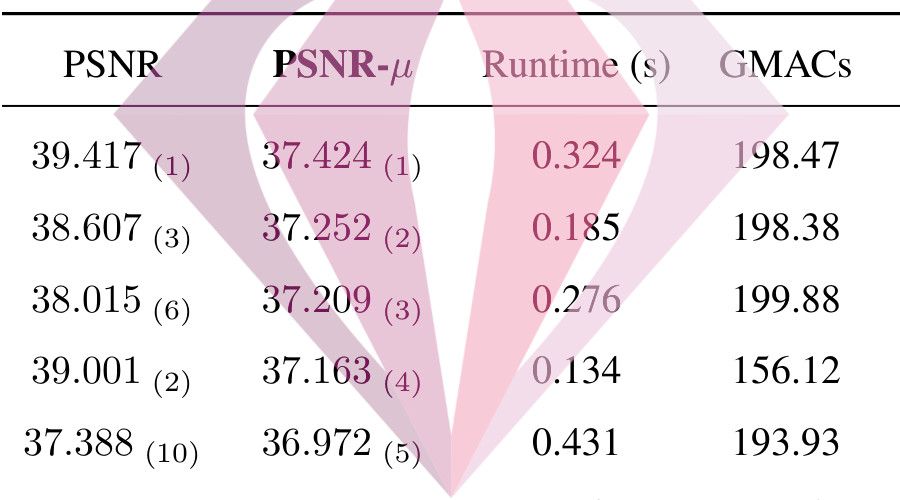 NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and ResultsCVPR Workshops, 2022
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and ResultsCVPR Workshops, 2022This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
-
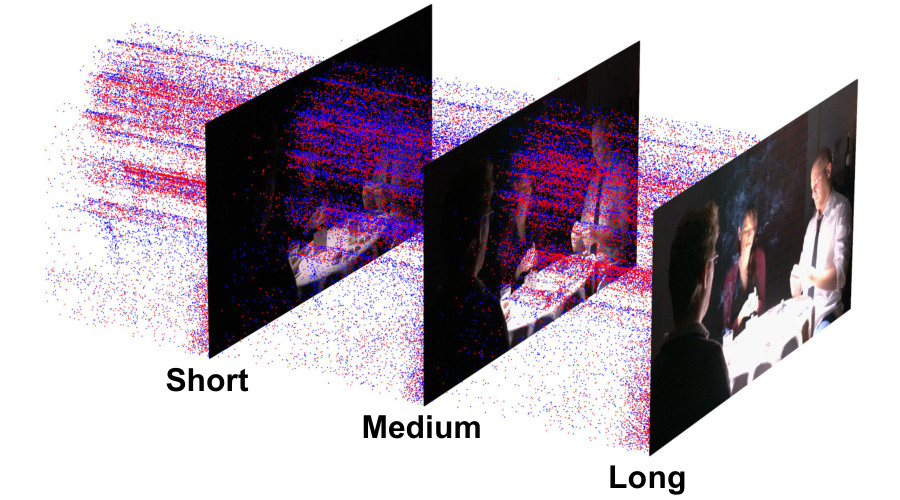 HDR Reconstruction from Bracketed Exposures and EventsBMVC (spotlight), 2022
HDR Reconstruction from Bracketed Exposures and EventsBMVC (spotlight), 2022Reconstruction of high-quality HDR images is at the core of modern computational photography. Significant progress has been made with multi-frame HDR reconstruction methods, producing high-resolution, rich and accurate color reconstructions with high-frequency details. However, they are still prone to fail in dynamic or largely over-exposed scenes, where frame misalignment often results in visible ghosting artifacts. Recent approaches attempt to alleviate this by utilizing an event-based camera (EBC), which measures only binary changes of illuminations. Despite their desirable high temporal resolution and dynamic range characteristics, such approaches have not outperformed traditional multi-frame reconstruction methods, mainly due to the lack of color information and low-resolution sensors. In this paper, we propose to leverage both bracketed LDR images and simultaneously captured events to obtain the best of both worlds: high-quality RGB information from bracketed LDRs and complementary high frequency and dynamic range information from events. We present a multi-modal end-to-end learning-based HDR imaging system that fuses bracketed images and event modalities in the feature domain using attention and multi-scale spatial alignment modules. We propose a novel event-to-image feature distillation module that learns to translate event features into the image-feature space with self-supervision. Our framework exploits the higher temporal resolution of events by sub-sampling the input event streams using a sliding window, enriching our combined feature representation. Our proposed approach surpasses SoTA multi-frame HDR reconstruction methods using synthetic and real events, with a 2dB and 1dB improvement in PSNR-L and PSNR-mu on the HdM HDR dataset, respectively.
-
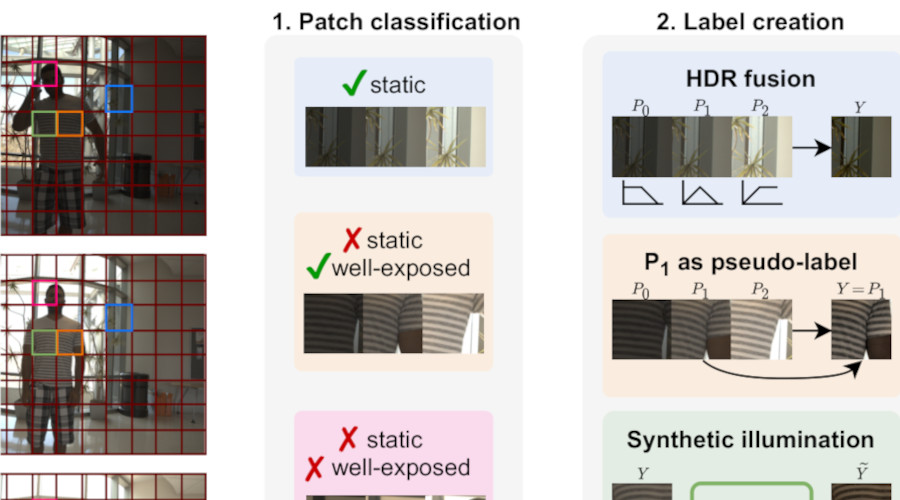 Self-supervised HDR Imaging from Motion and Exposure CuesarXiv:2203.12311 [cs.CV], 2022
Self-supervised HDR Imaging from Motion and Exposure CuesarXiv:2203.12311 [cs.CV], 2022Recent High Dynamic Range (HDR) techniques extend the capabilities of current cameras where scenes with a wide range of illumination can not be accurately captured with a single low-dynamic-range (LDR) image. This is generally accomplished by capturing several LDR images with varying exposure values whose information is then incorporated into a merged HDR image. While such approaches work well for static scenes, dynamic scenes pose several challenges, mostly related to the difficulty of finding reliable pixel correspondences. Data-driven approaches tackle the problem by learning an end-to-end mapping with paired LDR-HDR training data, but in practice generating such HDR ground-truth labels for dynamic scenes is time-consuming and requires complex procedures that assume control of certain dynamic elements of the scene (e.g. actor pose) and repeatable lighting conditions (stop-motion capturing). In this work, we propose a novel self-supervised approach for learnable HDR estimation that alleviates the need for HDR ground-truth labels. We propose to leverage the internal statistics of LDR images to create HDR pseudo-labels. We separately exploit static and well-exposed parts of the input images, which in conjunction with synthetic illumination clipping and motion augmentation provide high quality training examples. Experimental results show that the HDR models trained using our proposed self-supervision approach achieve performance competitive with those trained under full supervision, and are to a large extent superior to previous methods that equally do not require any supervision.
-
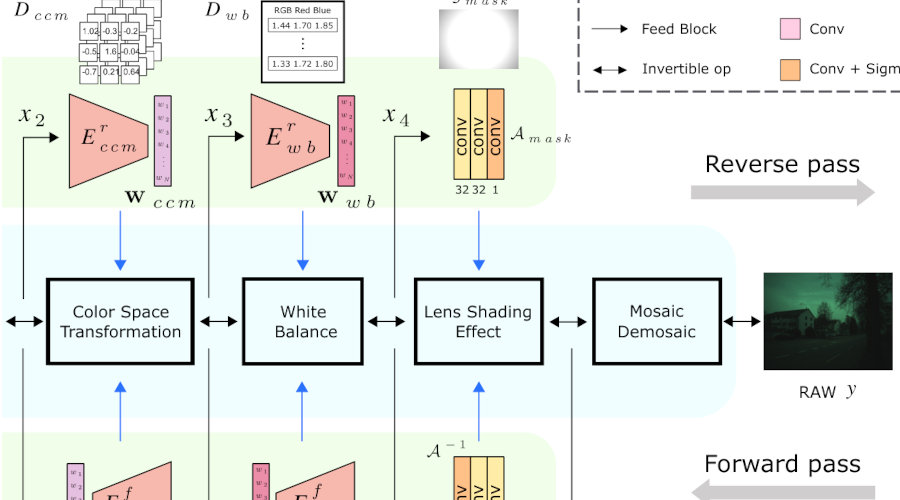 Model-Based Image Signal Processors via Learnable DictionariesAAAI (oral), 2022
Model-Based Image Signal Processors via Learnable DictionariesAAAI (oral), 2022Digital cameras transform sensor RAW readings into RGB images by means of their Image Signal Processor (ISP). Computational photography tasks such as image denoising and colour constancy are commonly performed in the RAW domain, in part due to the inherent hardware design, but also due to the appealing simplicity of noise statistics that result from the direct sensor readings. Despite this, the availability of RAW images is limited in comparison with the abundance and diversity of available RGB data. Recent approaches have attempted to bridge this gap by estimating the RGB to RAW mapping: handcrafted model-based methods that are interpretable and controllable usually require manual parameter fine-tuning, while end-to-end learnable neural networks require large amounts of training data, at times with complex training procedures, and generally lack interpretability and parametric control. Towards addressing these existing limitations, we present a novel hybrid model-based and data-driven ISP that builds on canonical ISP operations and is both learnable and interpretable. Our proposed invertible model, capable of bidirectional mapping between RAW and RGB domains, employs end-to-end learning of rich parameter representations, i.e. dictionaries, that are free from direct parametric supervision and additionally enable simple and plausible data augmentation. We evidence the value of our data generation process by extensive experiments under both RAW image reconstruction and RAW image denoising tasks, obtaining state-of-the-art performance in both. Additionally, we show that our ISP can learn meaningful mappings from few data samples, and that denoising models trained with our dictionary-based data augmentation are competitive despite having only few or zero ground-truth labels.
2021
-
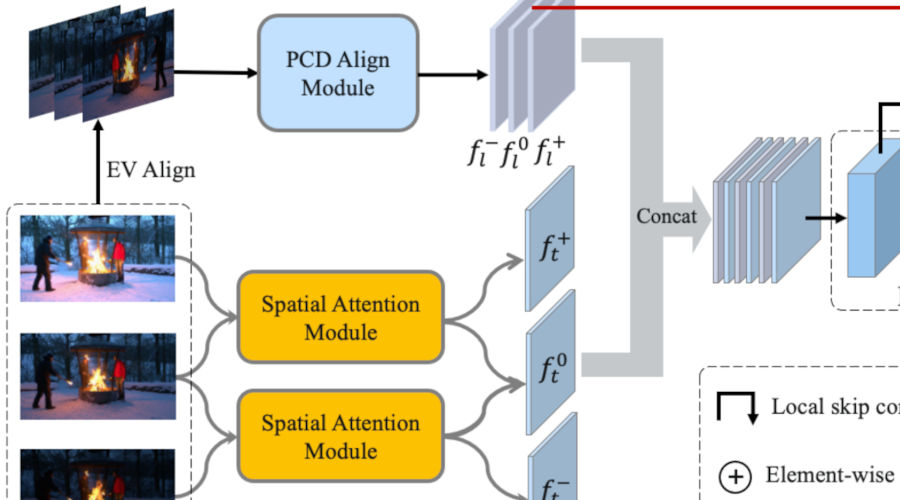 NTIRE 2021 Challenge on High Dynamic Range Imaging: Dataset, Methods and ResultsCVPR Workshops, 2021
NTIRE 2021 Challenge on High Dynamic Range Imaging: Dataset, Methods and ResultsCVPR Workshops, 2021This paper reviews the first challenge on high-dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2021. This manuscript focuses on the newly introduced dataset, the proposed methods and their results. The challenge aims at estimating a HDR image from one or multiple respective low-dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed by two tracks: In Track 1 only a single LDR image is provided as input, whereas in Track 2 three differently-exposed LDR images with inter-frame motion are available. In both tracks, the ultimate goal is to achieve the best objective HDR reconstruction in terms of PSNR with respect to a ground-truth image, evaluated both directly and with a canonical tonemapping operation.
2019
-
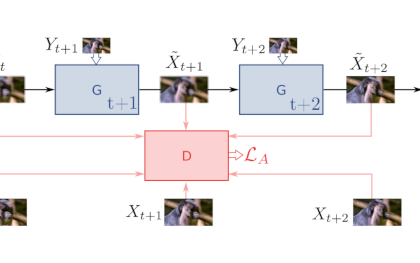 Perceptual Video Super Resolution with Enhanced Temporal ConsistencyarXiv:1807.07930v2 [cs.CV], 2019
Perceptual Video Super Resolution with Enhanced Temporal ConsistencyarXiv:1807.07930v2 [cs.CV], 2019With the advent of perceptual loss functions, new possibilities in super-resolution have emerged, and we currently have models that successfully generate near-photorealistic high-resolution images from their low-resolution observations. Up to now, however, such approaches have been exclusively limited to single image super-resolution. The application of perceptual loss functions on video processing still entails several challenges, mostly related to the lack of temporal consistency of the generated images, i.e., flickering artifacts. In this work, we present a novel adversarial recurrent network for video upscaling that is able to produce realistic textures in a temporally consistent way. The proposed architecture naturally leverages information from previous frames due to its recurrent architecture, i.e. the input to the generator is composed of the low-resolution image and, additionally, the warped output of the network at the previous step. Together with a video discriminator, we also propose additional loss functions to further reinforce temporal consistency in the generated sequences. The experimental validation of our algorithm shows the effectiveness of our approach which obtains images with high perceptual quality and improved temporal consistency.
2018
-
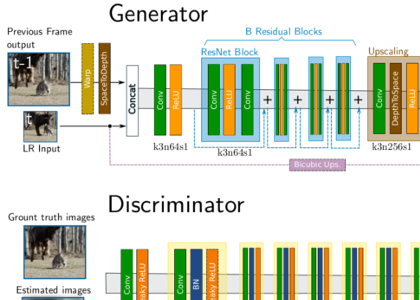 Photorealistic Video Super ResolutionECCV Workshops (PIRM), 2018
Photorealistic Video Super ResolutionECCV Workshops (PIRM), 2018In this work, we present a novel adversarial recurrent network for video upscaling that is able to produce realistic textures in a temporally consistent way. The proposed architecture naturally leverages information from previous frames due to its recurrent architecture, i.e. the input to the generator is composed of the low-resolution image and, additionally, the warped output of the network at the previous step.
2017
-
 Manifold Learning for Super ResolutionEduardo Pérez-PelliteroPhD Dissertation
Manifold Learning for Super ResolutionEduardo Pérez-PelliteroPhD Dissertation
Leibniz Universität Hannover, 2017The development pace of high-resolution displays has been so fast in the recent years that many images acquired with low-end capture devices are already outdated or will be shortly in time. Super Resolution is central to match the resolution of the already existing image content to that of current and future high resolution displays and applications. This dissertation is focused on learning how to upscale images from the statistics of natural images.
2016
-
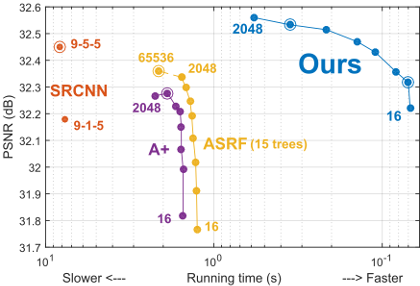 PSyCo: Manifold Span Reduction for Super ResolutionCVPR, 2016
PSyCo: Manifold Span Reduction for Super ResolutionCVPR, 2016In this paper we present a novel regression-based SR algorithm that benefits from an extended knowledge of the structure of both manifolds. We propose a transform that collapses the 16 variations induced from the dihedral group of transforms (i.e. rotations, vertical and horizontal reflections) and antipodality (i.e. diametrically opposed points in the unitary sphere) into a single primitive. The key idea of our transform is to study the different dihedral elements as a group of symmetries within the high-dimensional manifold. The experimental validation of our algorithm shows the effectiveness of our approach, which obtains competitive quality with a dictionary of as little as 32 atoms (reducing other methods’ dictionaries by at least a factor of 32) and further pushing the state-of-the-art with a 1024 atoms dictionary.
-
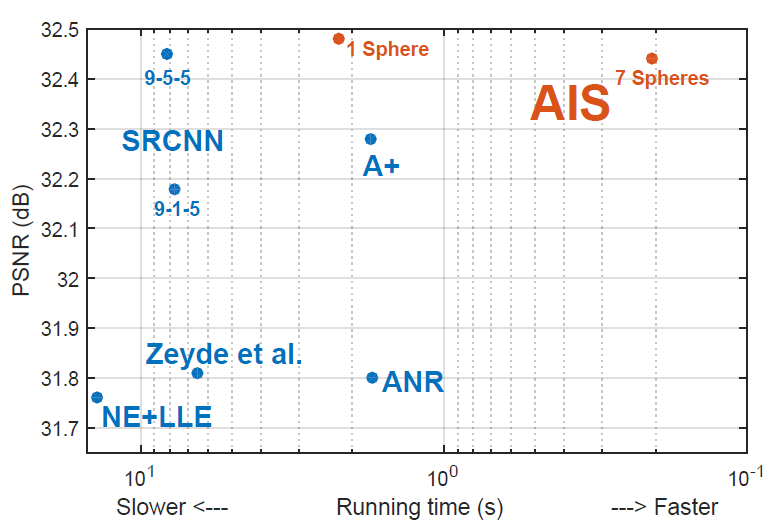 Antipodally Invariant Metrics For Fast Regression-based Super-ResolutionIEEE Trans. on Image Processing, 2016
Antipodally Invariant Metrics For Fast Regression-based Super-ResolutionIEEE Trans. on Image Processing, 2016In this paper we present a very fast regression-based algorithm which builds on densely populated anchored neighborhoods and sublinear search structures. Even though we validate the benefits of using antipodally invariant metrics, most of the binary splits use Euclidean distance, which does not handle antipodes optimally. In order to benefit from both worlds, we propose a simple yet effective Antipodally Invariant Transform (AIT) that can be easily included in the Euclidean distance calculation. We modify the original Spherical Hashing algorithm with this metric in our Antipodally Invariant Spherical Hashing scheme, obtaining the same performance as a pure antipodally invariant metric. We round up our contributions with a novel feature transform that obtains a better coarse approximation of the input image thanks to Iterative Back Projection.
-
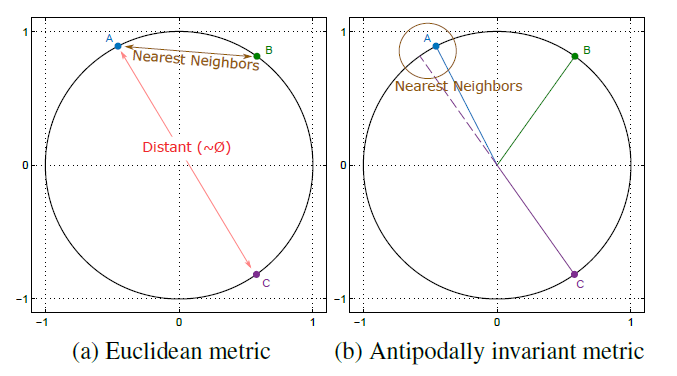 Half Hypersphere Confinement for Piecewise Linear RegressionWACV, 2016
Half Hypersphere Confinement for Piecewise Linear RegressionWACV, 2016In this paper we study the characteristics of the metrics best suited for the piecewise regression algorithms, in which comparisons are usually made between normalized vectors that lie on the unitary hypersphere. Even though Euclidean distance has been widely used for this purpose, it is suboptimal since it does not handle antipodal points (i.e. diametrically opposite points) properly. Therefore, we propose the usage of antipodally invariant metrics and introduce the Half Hypersphere Confinement (HHC), a fast alternative to Multidimensional Scaling (MDS) that allows to map antipodally invariant distances in the Euclidean space with very little approximation error. The performance of our method, which we named HHC Regression (HHCR), applied to Super-Resolution (SR) improves both in quality (PSNR) and it is faster than any other state-of-the-art method. Additionally, under an application-agnostic interpretation of our regression framework, we also test our algorithm for denoising and depth upscaling with promising results.
2015
-
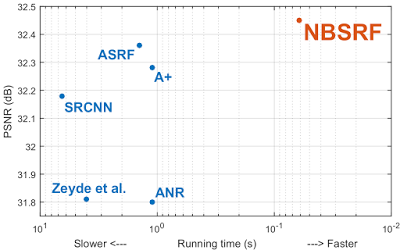 Naive Bayes Super-Resolution ForestJ Salvador, and E Pérez-PelliteroICCV, 2015
Naive Bayes Super-Resolution ForestJ Salvador, and E Pérez-PelliteroICCV, 2015This paper presents a fast, high-performance method for super resolution with external learning. The first contribution leading to the excellent performance is a bimodal tree for clustering, which successfully exploits the antipodal invariance of the coarse-to-high-res mapping of natural image patches and provides scalability to finer partitions of the underlying coarse patch space. During training an ensemble of such bimodal trees is computed, providing different linearizations of the mapping. The second and main contribution is a fast inference algorithm, which selects the most suitable mapping function within the tree ensemble for each patch by adopting a Local Naive Bayes formulation. The resulting method is beyond one order of magnitude faster and performs objectively and subjectively better than the current state of the art.
-
 Accelerating Super-Resolution for 4K UpscalingICCE, 2015
Accelerating Super-Resolution for 4K UpscalingICCE, 2015This paper presents a fast Super-Resolution (SR) algorithm based on a selective patch processing. Motivated by the observation that some regions of images are smooth and unfocused and can be properly upscaled with fast interpolation methods, we locally estimate the probability of performing a degradation-free upscaling. Our proposed framework explores the usage of supervised machine learning techniques and tackles the problem using binary boosted tree classifiers.
2014
-
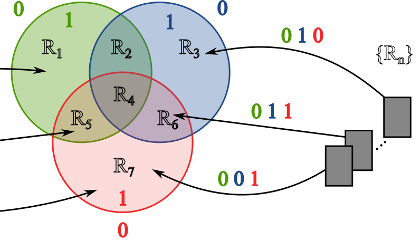 Fast Super-Resolution via Dense Local Training and Inverse Regressor SearchACCV, 2014
Fast Super-Resolution via Dense Local Training and Inverse Regressor SearchACCV, 2014Under the locally linear embedding assumption, SR can be properly modeled by a set of linear regressors distributed across the manifold. In this paper we propose a fast inverse-search approach for regression-based SR. Instead of performing a search from the image to the dictionary of regressors, the search is done inversely from the regressors’ dictionary to the image patches. Additionally, we propose an improved training scheme for SR linear regressors which improves perceived and objective quality. By merging both contributions we improve both speed and quality compared to the state-of-the-art.
-
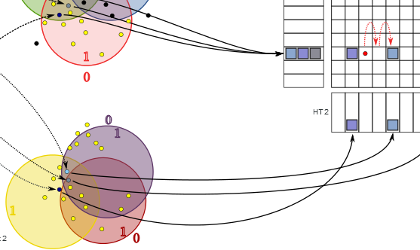 Fast Approximate Nearest-Neighbor Field by Cascaded Spherical HashingI Torres-Xirau, J Salvador, and E Pérez-PelliteroACCV, 2014
Fast Approximate Nearest-Neighbor Field by Cascaded Spherical HashingI Torres-Xirau, J Salvador, and E Pérez-PelliteroACCV, 2014We present an efficient and fast algorithm for computing approximate nearest neighbor fields between two images. Our method builds on the concept of Coherency-Sensitive Hashing (CSH), but uses a recent hashing scheme, Spherical Hashing (SpH), which is known to be better adapted to the nearest-neighbor problem for natural images. Cascaded Spherical Hashing concatenates different configurations of SpH to build larger Hash Tables with less elements in each bin to achieve higher selectivity. Our method amply outperforms existing techniques like PatchMatch and CSH, and the experimental results show that our algorithm is faster and more accurate than existing methods.
-
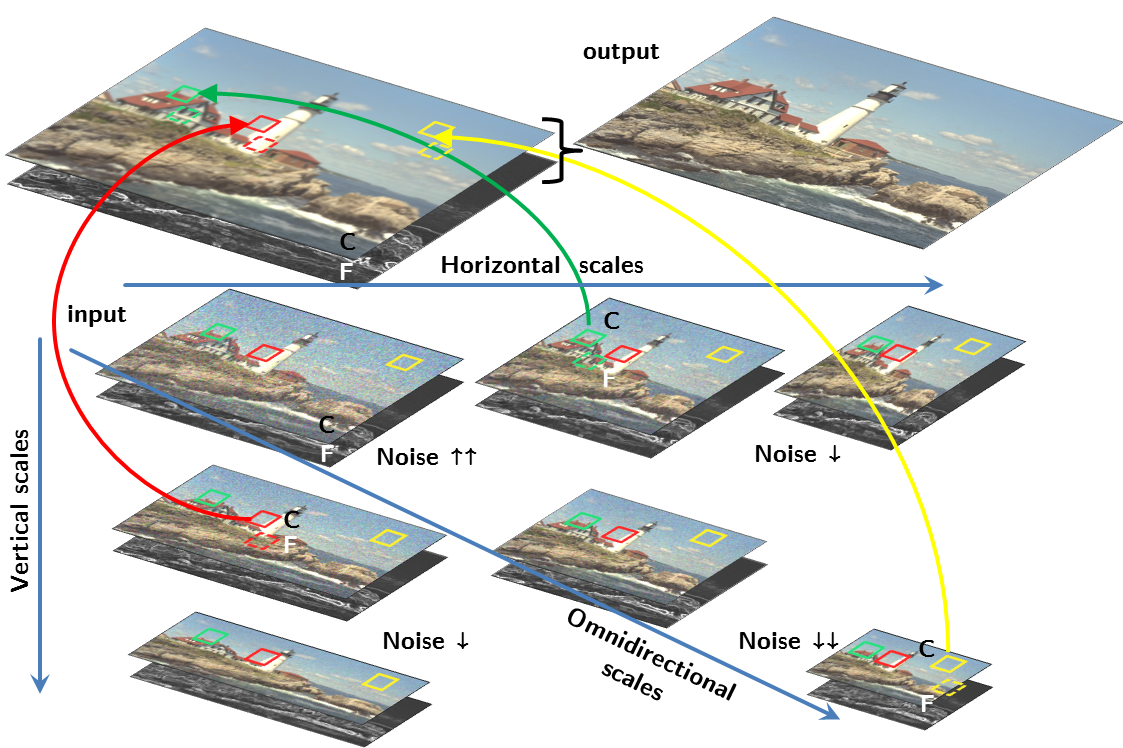 Robust Single-Image Super-Resolution using Cross-Scale Self-SimilarityJ Salvador, E Pérez-Pellitero, and A KochaleICIP, 2014
Robust Single-Image Super-Resolution using Cross-Scale Self-SimilarityJ Salvador, E Pérez-Pellitero, and A KochaleICIP, 2014We present a noise-aware single-image super-resolution (SISR) algorithm, which automatically cancels additive noise while adding detail learned from lower-resolution scales. In contrast with most SI-SR techniques, we do not assume the input image to be a clean source of examples. Instead, we adapt the recent and efficient in-place cross-scale self-similarity prior for both learning fine detail examples and reducing image noise. The experimental results show a promising performance, despite the relatively simple algorithm. Both objective evaluations and subjective validations show clear quality improvements when upscaling noisy images.
-
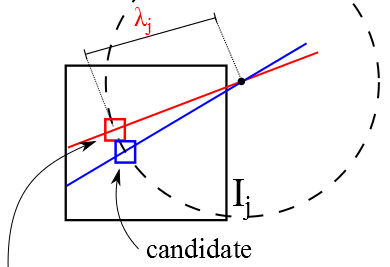 An Epipolar-Constrained Prior for Efficient Search in Multi-View ScenariosI Bosch, J Salvador, E Pérez-Pellitero, and J Ruiz-HidalgoEUSIPCO, 2014
An Epipolar-Constrained Prior for Efficient Search in Multi-View ScenariosI Bosch, J Salvador, E Pérez-Pellitero, and J Ruiz-HidalgoEUSIPCO, 2014In this paper we propose a novel framework for fast exploitation of multi-view cues with applicability in different image processing problems. An epipolar-constrained prior is presented, onto which a random search algorithm is proposed to find good matches among the different views of the same scene. This algorithm includes a generalization of the local coherency in 2D images for multi-view wide-baseline cases. Experimental results show that the geometrical constraint allows a faster initial convergence when finding good matches.
2013
-
 Bayesian region selection for adaptive dictionary-based Super-ResolutionBMVC, 2013
Bayesian region selection for adaptive dictionary-based Super-ResolutionBMVC, 2013This paper presents a novel sparse SR method, which focuses in adaptively selecting the optimal patches for the dictionary training. The method divides the training images into sub-image regions of sizes that preserve texture consistency. The best-representing region for each input LR patch is found through a Bayesian selection stage. In this selection process, SIFT descriptors are extracted densely from both input LR patches and regions and a local NBNN approach is used in order to efficiently handle the high number of different regions in the training dataset.